
AI/ML Based Network Slice and Network Resource Optimization
By Nextworks
AI and ML are key enablers to achieve full automation in next generation network slice and service orchestration platforms. Implementation of AI/ML in the Lifecycle Management (LCM) of end-to-end network slices and runtime operations, including planning, deployment, operating, scaling, and resource sharing. The target of using these enablers is to improve the optimization of network performances, while enhancing the users perceived experience. At the same time, AI/ML techniques can help in solving network management complexities brought by 5G, where several technologies and domains coexist for the provisioning of end-to-end services and slices.
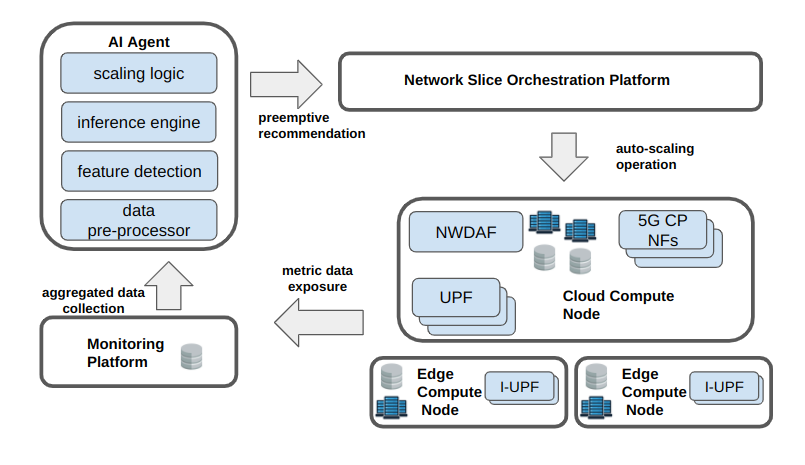
The AI/ML innovation scenario for the end-to-end network slice optimization in iNGENIOUS targets the trigger of a pre-emptive auto-scaling of local-edge and central User Plane Functions (UPFs).
The UPF is a primary network function (NF) of the 5G core network. The UPF, defined in 3GPP’s technical specification 23.501, is the interconnect point between the mobile infrastructure and the data network (providing encapsulation and decapsulation of the transport protocols employed) and the packet data unit (PDU) session anchor point for providing mobility within and between radio access technologies. UPFs and intermediate UPFs (iUPFs) can be virtualized, and be deployed within a dynamic cloud native compute infrastructure allowing packet processing and traffic aggregation to be performed closer to the network edge, increasing user plane performance efficiencies (e.g., latency, bandwidth).
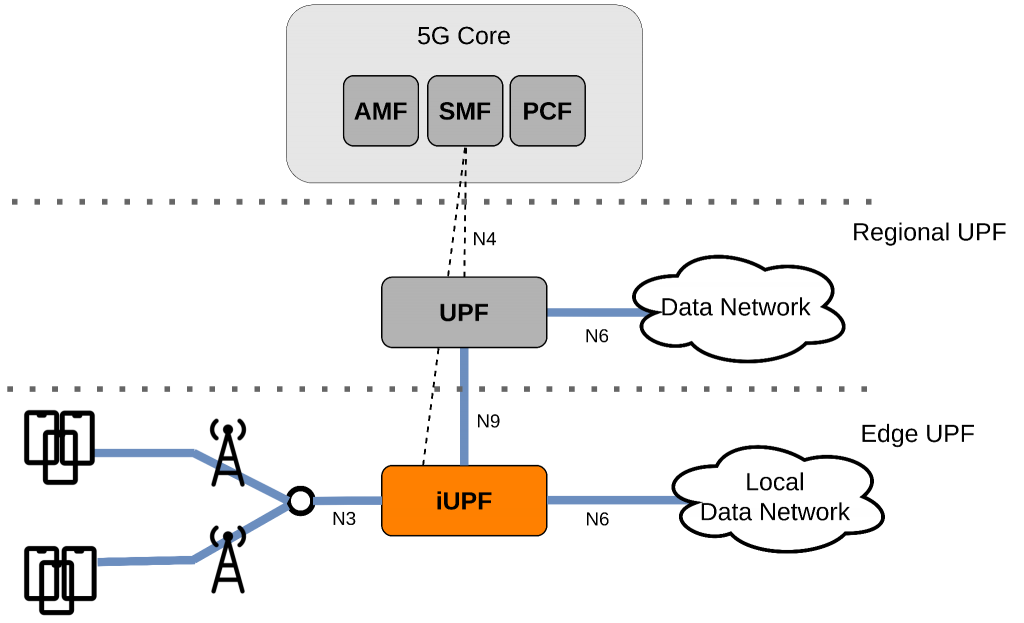
A single UPF instance can handle multiple protocol data unit (PDU) sessions, however the resources of a UPF instance are finite. As traffic load increases, to avoid degradations in service caused by finite resources, more UPF instances can be deployed and started, and likewise, an idle UPF instance can be terminated when the traffic is low. This process can be achieved in a closed-loop continuous fashion that monitors, measures, and assesses real-time network data, then automatically acts to optimise according to the Service Level Agreement (SLA).
To achieve this, the first step involves collecting monitoring data from the 5G infrastructure and applications. This information can be related to specific User Equipments (UEs), (mobility, communication pattern, etc.),NFs, network slices, or the network as a whole. UPF load information available from the NetWork Data Analytic Function (NWDAF), including CPU, memory, and disk usage, can be supplemented with user plane data like bandwidth, latency, packet loss, etc., as well as UE-related information (mobility, position, etc.) to get accurate predictions of future network conditions. In iNGENIOUS, a monitoring platform is being developed to retrieve and expose this aggregated data to an AI agent. The AI agent prepares the raw data for input to ML algorithms for traffic trend prediction.
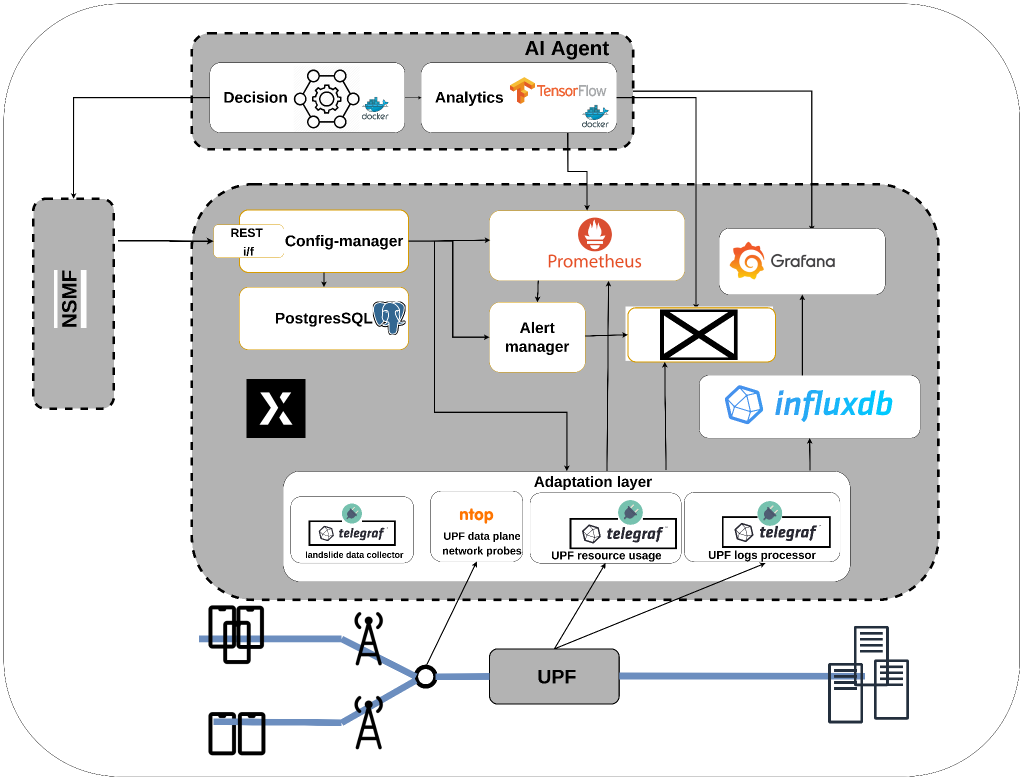
The monitoring platform provides both data storing and streaming functionalities, with proper interfaces exposed towards the AI/ML agent to consume the monitoring data. The data can be collected from different and heterogeneous data sources through the Adaptation Layer, which provides the necessary interfaces and logic to map the data from the sources to proper messages topics on the internal data bus. In particular, the Adaptation Layer is designed to be plug-in oriented, where each plug-in (or data-collection driver) collects data from a specific data source. This approach provides a high level of flexibility since the composition of the active plugins may vary with respect to the different network slices to be monitored or during the different phases of a network slice lifetime.
The AI Agent is divided into two functional blocks, Analytics and Decision. The live data inputs are obtained by the Analytics block through the monitoring platform, with analytics performance and results reported in Grafana. The Decision block passes the determined slice adaptations to the network slice orchestration components.
The Analytics block can be subdivided into 4-stages designed for robust functionality on real world data:
• Stage 1. Data pre-processing – real-time data contains many irregularities (ex. null values) unrelated to the useful information derived from the target analysis. This noise can directly affect the ability of models to reliably infer behaviours in the incoming data. The data pre-processor cleans and normalises the incoming dataset to avoid misbehaviour of the model on real world data.
• Stage 2. Feature detection – correlated time series data is analysed with respect to long term behaviours which create unique features that can be used to predict future trends in network behaviour. Selection of these features is achieved through the use of trained AI models capable of discriminating target ML input data.
• Stage 3. Inference engine – inference of future trends is performed using the identified features of the incoming dataset that are used as inputs in ML algorithms to determine the most probable future state of the system. These predictions are then sent to the scaling logic to determine the most appropriate system adaptation.
• Stage 4. Logic – the predictions of the state of the system are combined with operational parameters to decide if, how, and when an adaptation will optimise the resources of the system. The logic interacts with the network slice orchestration platform to accept any changes to the slice reconfiguration.
For what concerns the interaction with the network slice orchestration components, the AI/ML and Monitoring Platform offers a set RESTful APIs on top of the Config Manager and the AI/ML Engine. The purpose of the Config Manager API is to enable the automated configuration of specific monitoring jobs from the network slice orchestration platform. Indeed, during the provisioning of the end-to-end network slice instances, through this API the network slice orchestration platform can trigger the monitoring of specific service and network related metrics, to be then stored in the data lake, visualized in customized dashboards, and consumed by the AI/ML Engine. On the other hand, the AI/ML Engine offers an API that is exploited by the network slice orchestration platform to notify the analytics and decision functionalities about the evolution of network slices lifecycle (e.g., instantiation, scaling, termination) as well as on the result of the related lifecycle operations (i.e., success or failure) to help in the contextualization of data retrieved from the monitoring platform.
Further details on the iNGENIOUS solution for AI/ML based network slice and network resource optimization can be found in the project’s WP4 deliverables available here
